I’ve long wondered what the optimum starting ease settings are for learning vocabulary in anki. Starting ease is the primary setting the affects accuracy, workload, and ultimately how much I can learn in a given time. There’s supermemo’s theory page, but it’s not specific to japanese vocabulary or even language learning. I want to know my personal settings for the deck I’m studying so I decided analyze my anki learning data to find out.
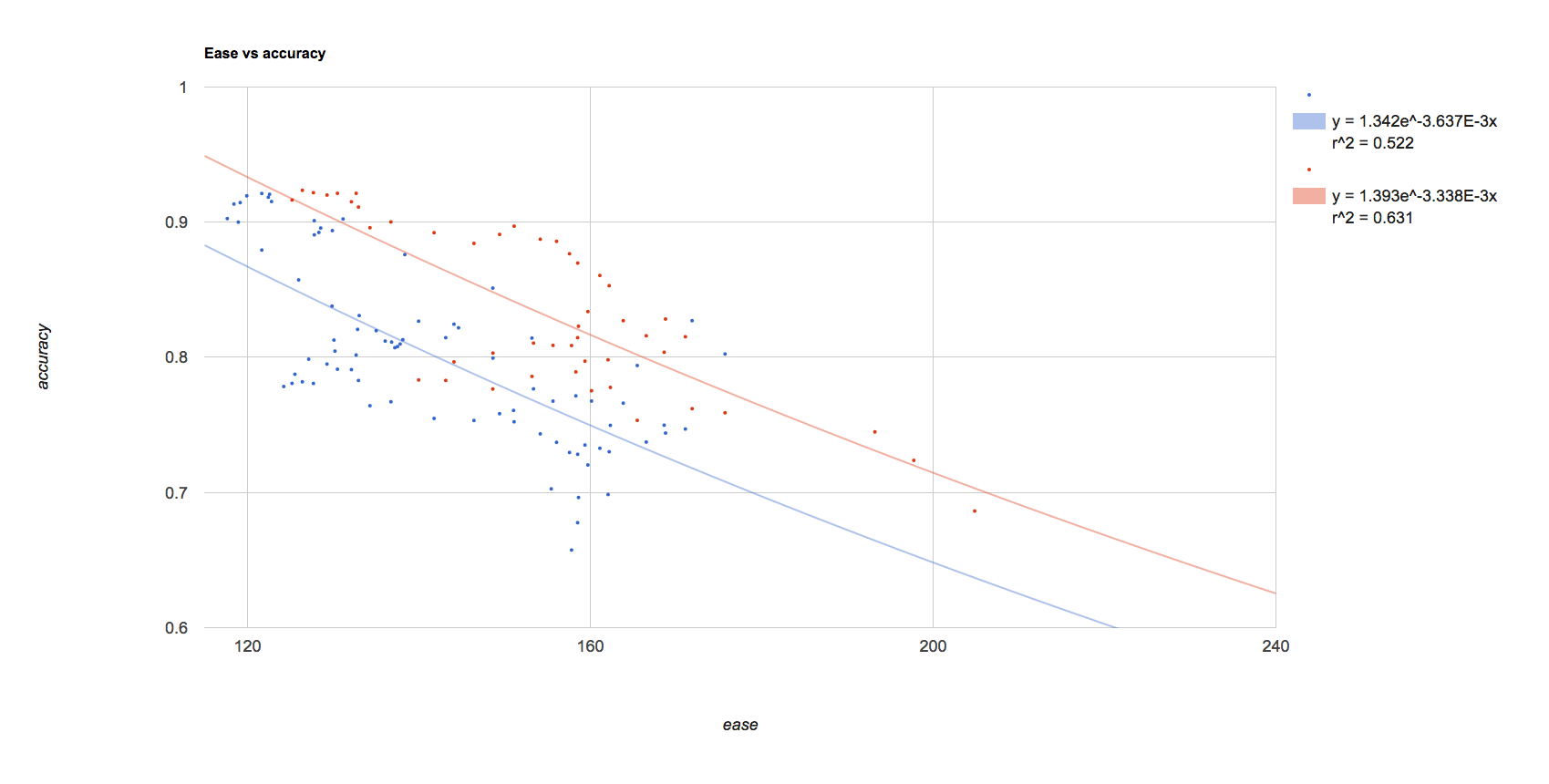
The first scatter chart shows the relationship between a card’s ease and my accuracy answering the card. The blue data points are from when I first started studying core vocabulary and was using a lot of filtered decks. I’ve since realized that filtered decks aren’t as efficient as simply using anki’s algorithm and sensible settings. I’m also guessing that there’s a learning effect making it easier to learn japanese vocabulary once I’m a few thousand words into learning. Either way, it seems that some combination of those factors is allowing me to be more accurate lately(red) as opposed to when I started(blue).
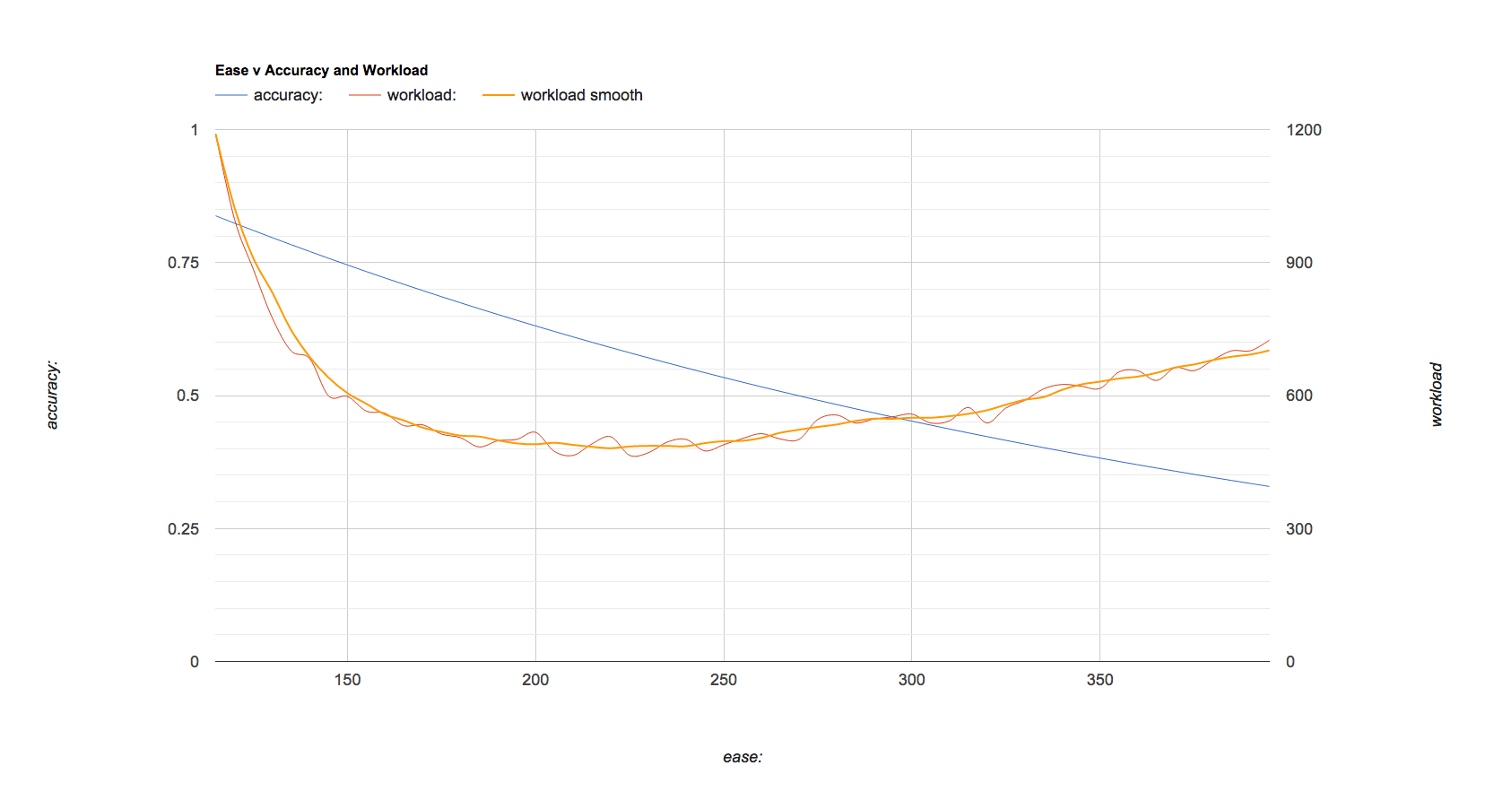
The second chart shows what happens when I simulate my workload for various values along the combined best fit curve. The blue line(left axis) is simply the combined line from the chart above. The red line(right axis) is the simulated workload and the yellow line(right axis) is a smoothed version of the red line. As you can see, on the left side of the chart, if I try for high accuracy, my workload is twice what it could be if I accepted a lower accuracy. At an ease of around 210, my accuracy should be around 61%, but my workload is about half what it is with ease 130 allowing me to study twice as many cards in the same amount of time.
The problem with the chart above is that the yellow line doesn’t accurately show how much of the vocabulary I actually “know” for any ease/accuracy setting. In other words, if I am getting 60% accuracy vs 80% accuracy, I “know” 20% less vocabulary, but it’s counted the same in the chart above. So the following chart is the same, only the yellow workload line is adjusted to account for accuracy, so that every point on the line represents the same number of known cards.
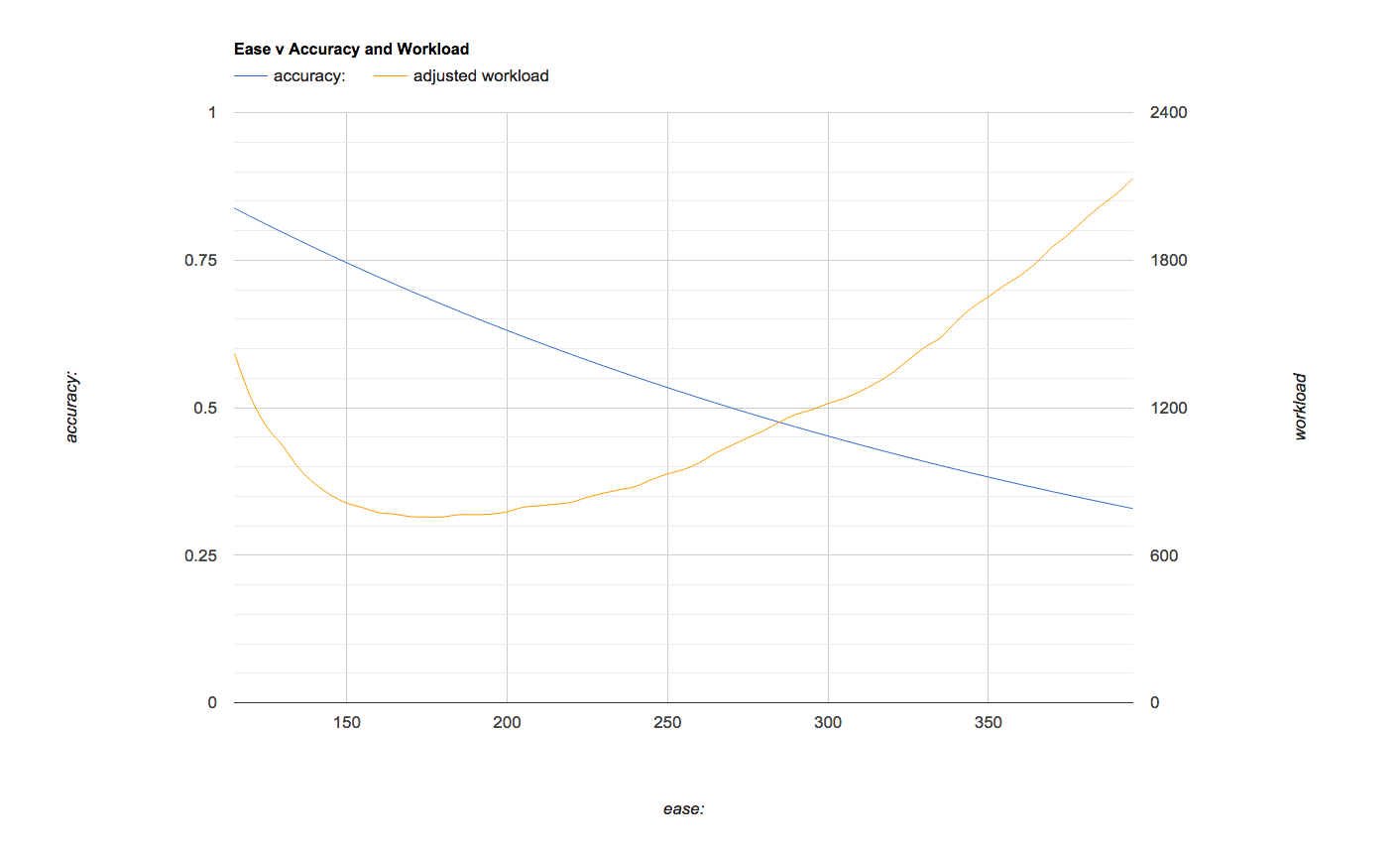
Judging by this last chart, my most efficient starting ease for my core vocabulary deck is around 175 which should put my accuracy around 67%. Lately, I’ve had my ease set to rather easy settings because it makes the learning process a lot more fun when I feel like I’m winning. However, I realized that the slope of that yellow line is so steep that a small sacrifice in accuracy should result in a large decrease in workload, allowing me to add more cards. So, I’ve decided to slowly raise my ease settings until I find a good comprise between accuracy, efficiency and enjoyment.
{kind=link}